
Lenna 이미지를 활용한 이미지 분석

로네 포르센이라는 스웨덴 출신 모델의 이미지를 활용하여 이미지 분석을 해보려고 한다.
이미지 불러오기
import cv2
img = cv2.imread(filename="Lenna_512x512.png", flags=cv2.IMREAD_GRAYSCALE)
본격적으로 이미지를 분석하기 전 이미지를 불러왔다.
이미지를 그레이 스케일(흑백)으로 불러오는 이유는 데이터 크기를 줄일 수 있고, 연산의 효율을 높여 더 정확한 분석이 가능해지기 때문이다.
이미지의 최소값, 최대값 찾기
(minVal, maxVal, minLoc, maxLoc) = cv2.minMaxLoc(src=img)
print(minVal, maxVal, minLoc, maxLoc)
데이터를 정규화할 때 활용하기 위해 이미지의 최소값과 최대값을 찾아야 한다.
아래는 찾아낸 이미지의 최소값과 최대값이다.

이미지 정규화
dst = cv2.normalize(src=img, dst=None, alpha=100, beta=200, norm_type=cv2.NORM_MINMAX)
위 이미지를 정규화하기 위한 코드이다.
- src=img: 원본 이미지를 입력으로 사용.
- dst=None: 출력 이미지 저장 위치. None으로 설정하면 새로운 이미지를 반환한다.
- alpha=100, beta=200: 정규화된 값의 범위를 [100, 200]으로 설정한다.
- norm_type=cv2.NORM_MINMAX: 원본 이미지의 최소값을 alpha로, 최대값을 beta로 변환하는 방식으로 정규화한다.
정규화된 이미지의 최소, 최대값 찾기
(minVal, maxVal, minLoc, maxLoc) = cv2.minMaxLoc(src=dst)
print(minVal, maxVal, minLoc, maxLoc)
이전에 사용했던 방식과 동일하게 값들을 찾아주면 된다.

위는 원본 이미지의 최소 최대값, 아래는 정규화된 이미지의 최소 최대값이 출력되었다.
순서대로 최소값, 최대값, 최소값 위치, 최대값 위치를 출력하였다.
이미지 출력
cv2.imshow(winname='LENNA', mat=img)
cv2.imshow(winname='NORM', mat=dst)
cv2.waitKey()
cv2.destroyAllWindows()

두 이미지의 차이는 최소 최대값을 어디서 찾았냐에 차이이다.
정규화된 데이터에서 최소 최대값을 찾게 되면 픽셀 값이 높아져서 사진의 밝기가 밝아지게 된다.
그렇게 원본 이미지보다 NORM이미지가 더 밝은 것을 볼 수 있다.
VGG19 모델
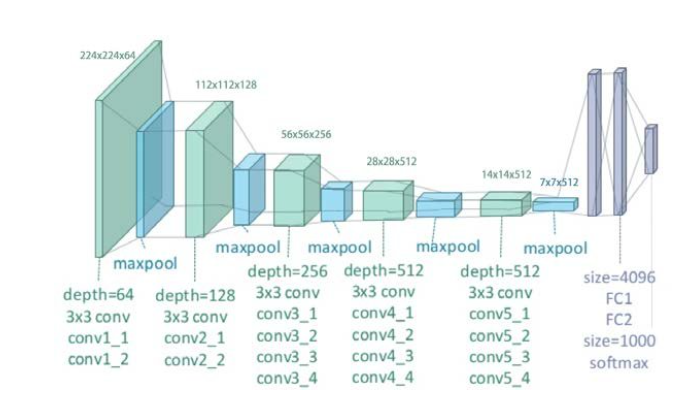
VGG19는 이미지 인식 및 분류에서 널리 사용되는 심층 합성곱 신경망(CNN) 모델이다.
3x3 크기의 작은 필터를 사용하여 해당 필터를 여러 겹으로 쌓아 올려 더 깊은 네트워크를 구축할 수 있다.
그렇게 구축된 깊은 네트워크를 통해 높은 정확도를 가질 수 있게 되었다.
VGG19 구조
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D, MaxPooling2D, Dropout
model = tf.keras.models.Sequential()
# 1. 첫 번째 Conv 블록
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu', input_shape=(224, 224, 3)))
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 2. 두 번째 Conv 블록
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=128, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 3. 세 번째 Conv 블록
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 4. 네 번째 Conv 블록
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 5. 다섯 번째 Conv 블록
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(Conv2D(filters=512, kernel_size=(3, 3), padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# 6. 완전 연결 층
model.add(Flatten())
model.add(Dense(units=4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(units=1000, activation='softmax'))
# 모델 컴파일
model.compile(optimizer=tf.keras.optimizers.Adam(0.003), loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
엄청나게 복잡하고 긴 코드양이다.
입력층을 설정할 때 (224, 224, 3) 으로 설정되어 있다.
원래는 이미지의 크기만 입력했지만 이미지의 컬러를 설정하기 위해 3을 작성해주었다.
3은 이미지의 색상 채널 수를 나타내며 3개의 채널은 RGB을 가진다.
따라서 input_shape=(224, 224, 3)는 224x224 크기의 RGB 컬러 이미지를 입력으로 받는다는 소리이다.
미리 학습된 가중치 불러오기
수업에서 미리 가중치 파일을 공유해주셨기에 해당 파일을 불러와 적용하도록 하겠다.
model.load_weights('vgg19_weights_tf_dim_ordering_tf_kernels.h5')
이미지 불러오기 및 전처리
import cv2
import numpy as np
# 이미지 불러오기
image1 = cv2.imread(filename='starrynight.jpeg')
cv2.imshow(winname='Image1', mat=image1)
cv2.waitKey()
cv2.destroyAllWindows()
# 이미지 크기 조정
new_image1 = cv2.resize(src=image1, dsize=(224, 224))
# 배치 차원 추가
new_image1 = new_image1[np.newaxis, :]
이미지의 크기를 224x224로 변경해주었고, 모델 입력에 맞게 차원을 추가해주었다.
예측 및 결과 확인
predict_image = model.predict(new_image1)
print(np.argmax(predict_image))
이제 해당 코드를 실행시켜 보자.
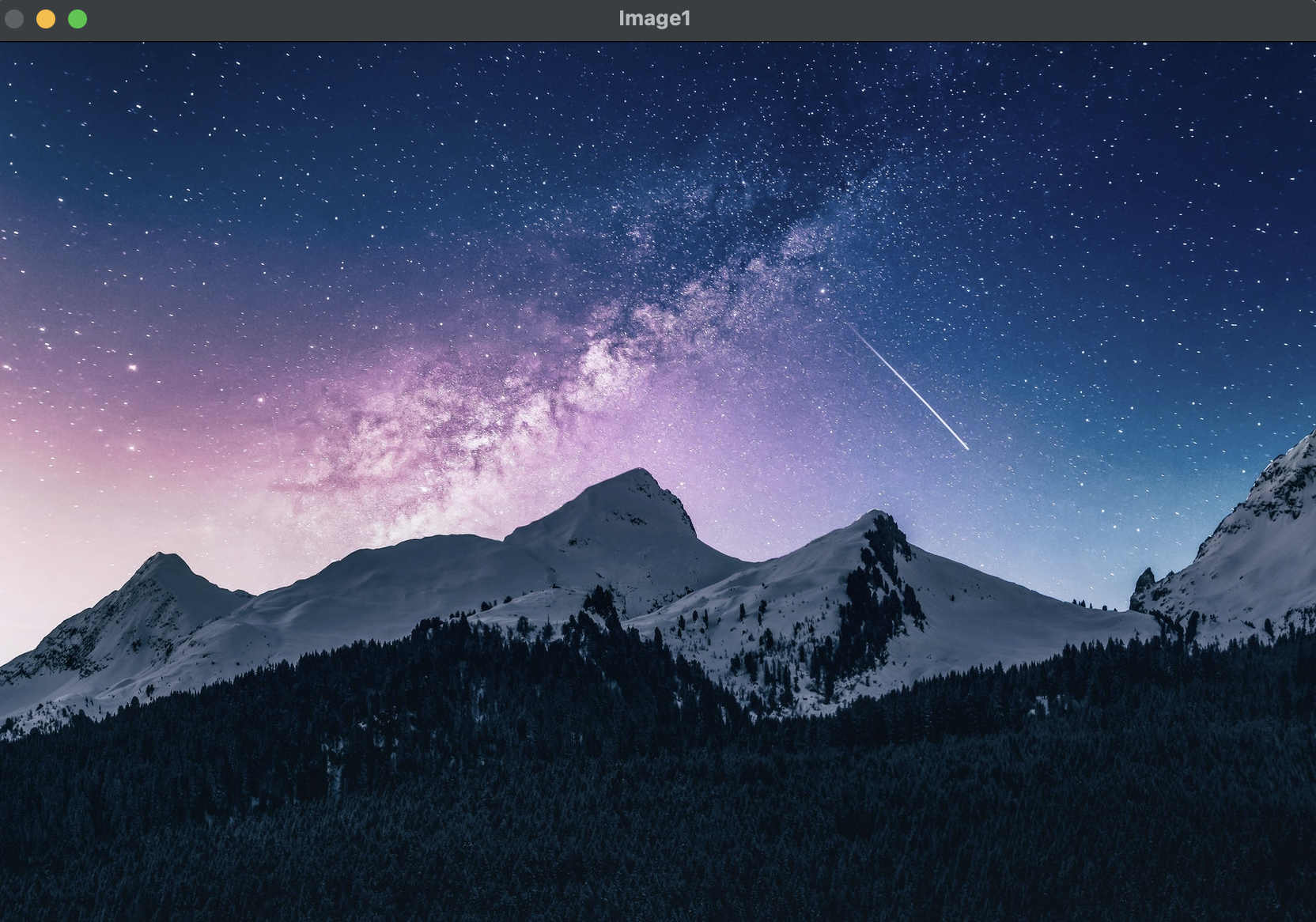

위 이미지에 대한 예측 결과는 970번이 나왔다.
위 번호는 classes.txt 안 데이터로 확인 가능하다.

970번 alp는 알프스 산맥을 나타내는 단어다.
내가 불러온 사진도 알프스 산맥의 사진이므로 모델이 예측한 값은 정답이다.
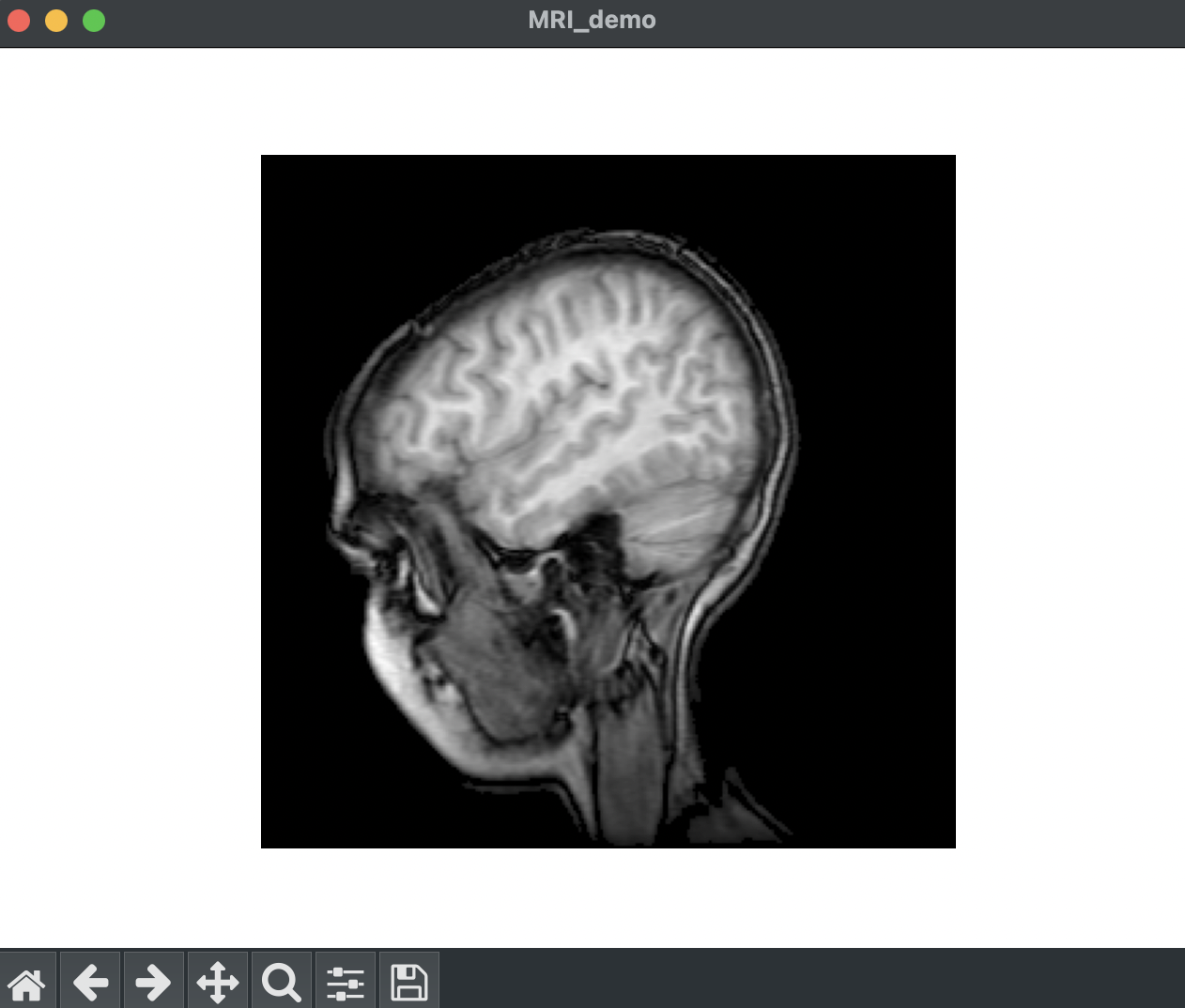
MRI 이미지
우리가 X-Ray와 MRI 검사 결과를 확인하면 이미지가 흑백으로 결과를 확인할 수 있다.
해당 검사 결과에서는 색상 정보보다는 밝기와 대비가 더 중요하기 때문이다.

그렇기에 위 컬러 MRI 사진을 흑백으로 바꿔 보려고 한다.
import matplotlib.pyplot as plt
import matplotlib.cbook as cbook
import numpy as np
with cbook.get_sample_data('s1045.ima.gz') as dfile:
im = np.frombuffer(dfile.read(), np.uint16).reshape((256, 256))
fig, ax = plt.subplots(num="MRI_demo")
ax.imshow(im, cmap='gray')
ax.axis('off')
plt.show()
이미지를 불러와 시각화 하기 위해 자료형을 변경하고 사이즈를 조정하였다.
그리고 inshow()함수에서 cmap='gray'로 설정하여 이미지를 흑백으로 출력하였다.
OpenCV 활용하기
1. 트랙바를 통한 이미지 가중합성하기
import cv2
image_1 = cv2.imread(filename='/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Image_1.jpg')
image_2 = cv2.imread(filename='/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Image_2.jpg')
우선은 라이브러리를 호출하고 각 이미지들을 불러왔다.
불러온 이미지는 아래와 같다.


이제 가중합성을 위한 함수를 선언해보자.
def changing_weight_value(x: int) -> None:
weight = x / 100 # weight 값을 0에서 1 사이로 변환
merged_image = cv2.addWeighted(src1=image_1, alpha=1 - weight,
src2=image_2, beta=weight, gamma=0)
cv2.imshow(winname="Display", mat=merged_image)
return None
- changing_weight_value(x): 트랙바에서 변경된 값을 인자로 받아 처리하는 콜백 함수
- weight = x / 100: 트랙바 값 x를 0에서 100 사이로 받고 이를 0에서 1 사이로 변환
- cv2.addWeighted: 두 이미지를 가중합성하는 함수
- src1: 첫 번째 이미지
- alpha: 첫 번째 이미지의 가중치(1 - weight)
- src2: 두 번째 이미지
- beta: 두 번째 이미지의 가중치(weight)
- gamma: 출력 이미지에 추가적으로 더할 값 (여기서는 0)
- cv2.imshow: 합성된 이미지를 윈도우에 표시
트랙바 생성 및 윈도우 설정
cv2.namedWindow(winname='Display')
cv2.createTrackbar('weight', 'Display',
0, 100, changing_weight_value)
cv2.waitKey(delay=0)
cv2.destroyAllWindows()
트랙바를 생성할 때 가지는 매개변수는 아래와 같다.
- 'weight': 트랙바 이름
- 'Display': 트랙바를 배치할 윈도우 이름
- 0: 트랙바의 초기값
- 100: 트랙바의 최대값
- changing_weight_value: 트랙바의 값이 변경될 때 호출되는 콜백 함수
실행결과
2. 필터 적용하기
import numpy as np
import cv2
original_image = cv2.imread(filename='/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Free_Image_6.jpg', flags=cv2.IMREAD_COLOR)
kernel1 = np.ones(shape=(3,3), dtype=np.float32) / 9
kernel2 = np.ones(shape=(9,9), dtype=np.float32) / 81
# 필터(weighted value)
average_image_3_by_3=cv2.filter2D(src=original_image,ddepth=-1,kernel=kernel1)
average_image_9_by_9 = cv2.filter2D(src=original_image, ddepth=-1, kernel=kernel2)
cv2.imshow(winname="Original Image", mat=original_image)
cv2.imshow(winname="3by3 filtered", mat=average_image_3_by_3)
cv2.imshow(winname="9by9 filtered", mat=average_image_9_by_9)
cv2.waitKey(delay=0)
cv2.destroyAllWindows()
필터의 크기를 3x3, 9x9로 설정하여 필터링한 원본 이미지와 비교해보자.



눈으로는 크게 차이가 느껴지지 않지만 필터의 크기가 커지면 이미지가 더 부드러워지고 블러링 효과가 강해진다고 한다.
그렇기에 필터가 큰 이미지를 보면 이미지의 디테일이 많이 손상됨을 확인할 수 있다.
3. 임계값 활용하기
임계값이란 신경망에서 뉴런이 활성화 될지의 여부를 결정하는 값이다.
임계값을 조절하여 출력 정도를 조절할 수 있다.
import cv2
color_image = cv2.imread("/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Free_Image_12.jpg", cv2.IMREAD_COLOR)
gray_image = cv2.cvtColor(src=color_image, code=cv2.COLOR_BGR2GRAY)
def changing_threshold(x:int) -> None:
(_, threshold_image) = cv2.threshold(src=gray_image,
thresh=x,
maxval=255,
type=cv2.THRESH_BINARY)
cv2.imshow(winname="THRESHOLD", mat=threshold_image)
return None
cv2.namedWindow(winname='Threshold Image')
cv2.createTrackbar("THRESHOLD","Threshold Image",
0, 255, changing_threshold)
# cv2.imshow('Threshold Image', gray_image)
cv2.waitKey()
cv2.destroyAllWindows()


임계값에 따라 이미지의 출력 정도가 달라짐을 확인할 수 있었다.
4. 윤곽선 추출하기
import cv2
original_img = cv2.imread('/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Free_Image_10.jpg')
image_gray = cv2.imread(filename='/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Free_Image_10.jpg',
flags=cv2.IMREAD_GRAYSCALE)
edge_image = cv2.adaptiveThreshold(src=image_gray, maxValue=255, adaptiveMethod=cv2.ADAPTIVE_THRESH_MEAN_C,
thresholdType=cv2.THRESH_BINARY, blockSize=9, C=0) # C는 -5 ~ 5 사이 자주 사용
cv2.imshow(winname='ORIGINAL', mat=original_img)
cv2.imshow(winname='EDGE', mat=image_gray)
cv2.waitKey()
cv2.destroyAllWindows()


5. 이미지 합성하기
우선 합성할 이미지 두개를 불러와 확인해보자.
import cv2
import numpy as np
front_image = cv2.imread('/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Front_Image.jpg',
flags=cv2.IMREAD_COLOR)
background_image = cv2.imread(filename='/Users/ansejun/Desktop/Python3/ABC/4주차/0__240725/Background_Image.jpg',
flags=cv2.IMREAD_COLOR)
# 원본 이미지 보기
cv2.imshow(winname='Front Image', mat=front_image)
cv2.imshow(winname='BG image', mat=background_image)
cv2.waitKey()
cv2.destroyAllWindows()

이제 두 이미지를 합성하기 위한 준비를 해보자.
# 녹색 HSV 확인하기 HUE
image_hsv = cv2.cvtColor(src=front_image, code=cv2.COLOR_BGR2HSV)
green_lower_bound = np.array([40, 100, 50]) # 녹색의 하한선
green_upper_bound = np.array([80, 255, 255]) # 녹색의 상한선
# mask image
mask_image = cv2.inRange(src=image_hsv, lowerb=green_lower_bound, upperb=green_upper_bound)
cv2.imshow(winname='Mask image', mat=mask_image)
cv2.waitKey()
cv2.destroyAllWindows()
# inverse image
inverse_mask_image = cv2.bitwise_not(src=mask_image)
cv2.imshow(winname='Inverse mask image', mat=inverse_mask_image)
cv2.waitKey()
cv2.destroyAllWindows()
# 녹색 픽셀들만 추출하기
extract_green_pixels = cv2.bitwise_and(src1=front_image, src2=front_image, mask=mask_image)
cv2.imshow(winname='Extract green image', mat=extract_green_pixels)
cv2.waitKey()
cv2.destroyAllWindows()
# 녹색 아닌 픽셀만 추출하기
not_extract_green_pixels = cv2.bitwise_and(src1=front_image, src2=front_image, mask=inverse_mask_image)
cv2.imshow(winname='NOT Extract green image', mat=not_extract_green_pixels)
cv2.waitKey()
cv2.destroyAllWindows()
# 녹색과 겹치는 배경 추출하기
extract_green_background_image = cv2.bitwise_and(src1=background_image, src2=background_image,
mask=mask_image)
cv2.imshow(winname='Extract green background image', mat=extract_green_background_image)
cv2.waitKey()
cv2.destroyAllWindows()





이제 합성할 두 이미지에 대한 처리가 끝났으니 두 이미지를 합성해보자.
merge_image = cv2.bitwise_or(src1=not_extract_green_pixels, src2=extract_green_background_image)
cv2.imshow(winname='Merge image', mat=merge_image)
cv2.imwrite(filename='Fake_image.jpg', img=merge_image)
cv2.waitKey()
cv2.destroyAllWindows()

두 이미지가 완벽하게 합성되었다.
'Python > 데이터분석(ABC 부트캠프)' 카테고리의 다른 글
| [26일차] ABC 부트캠프 / NVIDIA 딥러닝 기초 과정 (0) | 2024.08.04 |
|---|---|
| [25일차] ABC 부트캠프 / RNN (0) | 2024.07.28 |
| [23일차] ABC 부트캠프 / CNN 모델 (0) | 2024.07.28 |
| [22일차] ABC 부트캠프 / MNIST 숫자 이미지 분류 및 Keras 기본 개념 (0) | 2024.07.28 |
| [21일차] ABC 부트캠프 / 머신러닝 퀴즈 해결 및 신경망 (0) | 2024.07.26 |
