
19일차 학습에 들어가기 전에 간단한 복습을 하였다.
- 머신러닝을 하기 위해서는 정답 데이터를 알고 있어야 한다.
- 가중치의 오차를 최소화 하기 위해 미분값이 0이 될때까지 반복하여 손실을 낮춰야 한다.
- 숫자로 된 선형 데이터가 학습하기에 적합하다.
위 세가지 정보를 명심하고 오늘 학습으로 넘어가고자 한다.
sklearn의 datasets 모듈의 Iris 데이터 활용
18일차에도 Iris 데이터셋을 활용한 예제를 다뤘었다.
오늘은 똑같은 데이터셋을 KNN 분류기가 아닌 선형 회귀 모델을 학습시켜 실습해보고자 한다.
# 라이브러리 호출
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_iris
import numpy as np
# 데이터셋 불러오기
iris = load_iris()
X = iris.data # 데이터
y = iris.target # 정답
print(X.shape, y.shape) # 각각의 데이터셋 크기 확인
우선 학습에 필요한 데이터셋 및 모델, numpy 라이브러리를 호출해야 한다.
또한 데이터셋을 불러와 해당 데이터셋의 크기를 확인해보고자 한다.

X에 저장된 데이터의 크기는 150개의 행 갯수와, 4개의 열 갯수를 가지고 있다.
또한 Y는 150개의 요소를 가지는 1차원 배열이다.
그렇기에 출력창에 150 이외의 숫자가 표시되지 않는다.
그렇다면 두 데이터 간 갯수의 차이는 없으므로 학습할 데이터를 분할하도록 하자.
from sklearn.model_selection import train_test_split
(X_train, X_test, y_train, y_test) = train_test_split(X, y, test_size=0.2)
위 코드를 통해 데이터와 타겟을 0.2 비율로 테스트 훈련 데이터와 테스트 데이터로 분할해 주었다.
분할한 데이터를 통해 선형을 학습시켜 보자.
from sklearn.linear_model import LinearRegression
regression = LinearRegression() # 선형 회귀 모델 생성
regression.fit(X=X_train, y=y_train) # 훈련 세트를 사용하여 모델 학습
선형 회귀 모델을 생성하기 위해 클래스에 대한 객체를 생성해 주었다.
이제 생성한 객체를 사용하여 훈련 세트를 통한 모델 학습을 시켜주었다.
이제 학습한 결과를 확인해보자.
#regression.coef_ wight 가중치
#regression.intercept_ 편향
#regression.score 모델의 성능
# 학습 결과 확인
print(f'가중치 : {regression.coef_}')
print(f'편향 : {regression.intercept_}')
print(f'훈련하면서 맞춘 정답은 : {regression.score(X=X_train, y=y_train)}')
정확도가 무려 9할이 넘는 높은 정확도가 나왔다.
이제 가중치와 편향을 구했으니 테스트 데이터에 대한 예측을 수행할 수 있다.
y_predicted = regression.predict(X=X_test)
print(f'내가 예상한 정답은 : {y_predicted}')
print(f'이미 가진 정답은 : {y_test}')
print(np.round(y_predicted).astype(int))
print(y_test)
predict 메서드를 사용하여 테스트 데이터에 대한 예측을 수행한다.
또한 예측된 값을 반올림하고 정수형으로 변경하여 실제 정답과 비교한다.
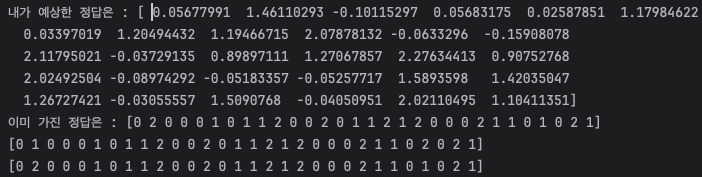
예상한대로 최종적으로 정수형으로 변경하여 데이터를 확인해보면 높은 정확도를 띄고 있음을 확인할 수 있다.
이제 테스트까지 마친 후 정답률을 확인해보자.
from sklearn.metrics import accuracy_score
rounded_y_predicted = np.round(y_predicted).astype(int)
accuracy_score(y_pred=rounded_y_predicted, y_true=y_test)
print(f'테스트 한 모델의 정확도 : {accuracy_score(y_pred=rounded_y_predicted, y_true=y_test)}')이번에는 accuracy_score 함수를 사용하여 반올림된 예측값과 실제 정답간의 정확도를 계산하고 출력하였다.

이제 예측값과 실제 정답을 비교하는 크래프를 그려보자.
from matplotlib import pyplot as plt
plt.plot(rounded_y_predicted, y_test, color='red', linewidth=4)
plt.show()
matplotlib을 사용하여 예측값과 실제 정답을 비교하는 그래프를 그려보았다.

정확도가 100%가 아니기에 여러개의 선형이 그려졌다.
이렇게 선형회귀를 통해서도 데이터를 분류할 수 있다.
위 같은 방법으로 선형회귀를 사용하여 데이터셋을 분류하였지만, 본래 선형 회귀는 실수를 예측하는데 사용하며, 실제 분류 문제에서는 분류 알고리즘을 사용하는게 더 효율적이라고 한다.
sklearn의 datasets 모듈의 diabets 데이터 활용
해당 데이터셋은 당뇨병 데이터셋이며, Iris와 비슷한 형식으로 저장되어 있다.
이제 당뇨와 BMI의 관계를 알아보고자 해당 데이터셋을 활용하고자 한다.
한번 데이터셋을 불러와 형태를 확인해보자.
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn import datasets
(diabetes_X, diabetes_y) = datasets.load_diabetes(return_X_y=True)
print(f'Data : {diabetes_X}')
print(f'정답 : {diabetes_y}')
이제 불러온 데이터셋을 확인해보자.

우선 위 사진과 같이 데이터들이 저장되어 있다.
정답에 담긴 데이터들은 당뇨 수치로 보이나 Data에 든 값들은 감이 잡히지 않는다.
그러나 어찌저찌 2번째 인덱스의 값이 BMI를 나타냄을 알게 되었고, BMI만 추출하도록 하자.
# 하나의 특징(BMI)만 추려내서 2차원 배열로 만든다. BMI 특징의 인덱스가 2이다.
diabetes_X_new = diabetes_X[:, np.newaxis, 2]
print(diabetes_X_new)
print(diabetes_X_new.shape)
우선 배열에서 BMI만을 추출하여 2차원베열로 변환해야 한다.
이때 2차원 배열로 변환해야 하는 이유는 입력 데이터는 항상 2차원의 성격을 가지고 있어야 하기 때문이다.
이제 데이터를 분할해보자.
# 학습 데이터와 테스트 데이터를 분리한다.
from sklearn.model_selection import train_test_split
(X_train, X_test, y_train, y_test) = train_test_split(diabetes_X_new, diabetes_y,
test_size=0.2, random_state=0)
train_test_split 함수를 사용하여 테스트 데이터를 전체 데이터의 20%로 할당한다.
'random_state=0' 은 재현성을 위해 난수 초기값을 설정했다.
이제 모델을 학습시켜보자.
regression : LinearRegression = LinearRegression()
regression.fit(X=X_train, y=y_train) # regression => 학습 시킨 모델
print(regression.score(X=X_train, y=y_train))
마찬가지로 객체를 생성하여 모델을 생성해주고 학습 데이터를 넣어 모델을 학습시켜준다.
그리고 훈련 데이터에 대한 모델의 성능을 확인해보자.

엄청나게 낮은 정확도를 알 수 있다.
그렇다면 테스트 데이터에 대한 예측을 수행해보자.
y_predicted = regression.predict(X=X_test).astype(int)
print(y_predicted)
print(y_test)
예측한 값을 정수로 변경하여 출력하였다.
그렇게 실제 목표값과 비교하여 보자.

학습 데이터 자체의 정확도도 너무 낮았고 테스트 데이터로 예측한 데이터의 정확도도 눈에 보이게 낮은걸 확인할 수 있다ㅠ
이제 이런 엉터리 학습 모델을 가지고 시각화 하면 어떻게 될까?
plt.plot(y_predicted, y_test, 'o')
plt.show()

정말 연관없게 생긴 시각화 데이터가 탄생하였다.
이는 모델의 정확도가 너무 낮은 탓인데, 정확도가 낮은 이유는 여러가지가 있지만 당뇨병과 BMI의 연관성이 낮아서 발생할 수 있다.
KNN 분류 모델을 사용하여 견종 분류하기
강아지의 길이와 키를 지정하여 해당 강아지의 정보를 토대로 견종을 맞추는 프로그램을 만들어 볼 예정이다.
견종을 닥스훈트와 사모예드로 설정하고 데이터를 준비해야 한다.
dach_length = [77, 78, 85, 83, 73, 77, 73, 80]
dach_height = [25, 28, 29, 30, 21, 22, 17, 35]
samo_length = [75, 77, 86, 86, 79, 83, 83, 88]
samo_height = [56, 57, 50, 53, 60, 53, 49, 61]
우선 길이와 키를 각각 리스트로 정의하였다.
이제 입력 데이터를 2차원 배열로 만들어 줘야 한다.
또한 Iris 데이터셋의 타겟처럼 해당 데이터의 라벨을 생성해야 한다.
# 키와 길이를 2차원 배열로 생성
# 견종별 라벨링
d_data = np.column_stack((dach_length, dach_height))
d_label = np.zeros(len(d_data))
print(d_label)
s_data = np.column_stack((samo_length, samo_height))
s_label = np.ones(len(s_data))
print(s_label)
코드의 주석대로 입력데이터를 2차원 배열로 생성해야 하므로 키와 길이를 2차원 배열로 합쳐주었다.
또한, 견종별로 구분할 수 있게 라벨링을 통해 구별할 수 있게 지정한다.
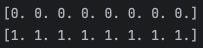
0이면 닥스훈트가, 1이면 사모예드로 라벨링 하였다.
이제 모델을 학습시키기 위한 준비를 해보도록 하자.
newdata = [[78, 35]] # 새로운 데이터 - 어떤 종류인가요?
dog_classes = {0: 'Dachhund', 1 : 'Samoyed'}
k = 3 # KNN 분류 알고리즘에서 사용할 이웃의 수
우선 어느 견종일지 궁금한 강아지의 신체 스펙을 작성해준다.
또한 딕셔너리 형태의 변수를 작성하여 라벨링 값에 따라 견종을 value값에 할당하도록 작성해주었다.
그리고 KNN 분류에서 사용할 이웃의 수도 설정하였다.
이제 모델을 학습 및 예측해보자.
from sklearn.neighbors import KNeighborsClassifier
knn: KNeighborsClassifier = KNeighborsClassifier(n_neighbors=k) # 클래스 knn은 객체이다.
# numpy 병합
dogs = np.concatenate((d_data, s_data)) # 16마리 순서로 정해진 개 데이터
labels = np.concatenate((d_label, s_label))
knn.fit(X=dogs, y=labels)
y_predict = knn.predict(X=newdata)
print(y_predict)
print(f'새로운 데이터 : {newdata} - 판정결과 : {dog_classes[y_predict[0]]}')
이제 두 데이터셋들을 병합해주고 데이터의 갯수가 몇개 되지 않기 때문에 훈련 데이터와 테스트 데이터를 나누지 않고 학습하였다.
그리고 학습시킨 모델을 활용하여 새로운 데이터의 품종을 예측해보았다.

내가 입력한 강아지의 스펙을 토대로한 견종은 닥스훈트로 판정되었다.
KNN 분류 모델과 선형회귀를 사용한 분류를 사용해보았다.
머신러닝이란 정말 어려운 분야인 것 같다.
내일은 또 어떤 어려운 것을 배울까 슬슬 무섭기 시작한다.
'Python > 데이터분석(ABC 부트캠프)' 카테고리의 다른 글
| [21일차] ABC 부트캠프 / 머신러닝 퀴즈 해결 및 신경망 (0) | 2024.07.26 |
|---|---|
| [20일차] ABC 부트캠프 / 제 2회 ESG Day (2) | 2024.07.21 |
| [18일차] ABC 부트캠프 / Numpy 기초 및 머신러닝 (1) | 2024.07.21 |
| [17일차] ABC 부트캠프 / 빅데이터 분석 및 기초 통계, 딥러닝 기초 (0) | 2024.07.21 |
| [16일차] ABC 부트캠프 / 데이터 수집 및 시각화 팀 프로젝트 (0) | 2024.07.17 |
