
오늘은 코드를 직접 실행해보며 Numpy 기초를 알아보았다.
개발 IDE는 기존에 쓰던 VSCode가 아닌 PyCharm을 다운받아 사용하였다.
https://www.jetbrains.com/ko-kr/pycharm/download/?section=mac
PyCharm 다운로드: 데이터 과학 및 웹 개발을 위해 JetBrains가 만든 Python IDE
www.jetbrains.com
IDE를 다운받았으면 파이썬 버전 설정과 같은 환경설정을 맞춰주고, 사용하는 라이브러리들을 다운로드 받아야 한다.
변수 선언
파이썬에서 변수를 생성하는 방법은 1주차때도 배웠었다.
그러나 4주차인 지금 다시 언급하는 이유는 파이썬에서 변수를 선언할 때 자료형을 명시할 수 있는 방법이 있기 때문이다.
# 기존 방식
ex1 = 10
# 자료형을 명시
ex2:int = 15
위 방식대로 변수명 뒤에 콜론을 붙여주고 자료형을 작성하면 변수의 데이터 타입을 명시하며 데이터를 변수에 저장할 수 있다.
함수 생성
함수는 실행코드를 묶어서 실행하기 위해 사용하는 방식이다.
함수를 호출하면 해당 함수의 실행코드들이 실행되어 실행할 때마다 코드들을 번거롭게 작성할 필요가 없다.
그럼 함수는 어떻게 만드는 걸까
# 사용방식
def 함수명(매개변수):
실행코드...
함수를 만드는 과정은 두가지로 축약할 수 있다.
1. 우선 def 뒤 함수명을 작성하고 콜론을 찍는다.
2. 아랫줄에 들여쓰기를 하여 실행코드를 작성한다.
만약 매개변수를 전달받는다면 전달받은 매개변수를 활용하여 실행코드를 작성할 수 있을 것이다.
배열과 리스트의 차이
한개의 변수에 여러 데이터를 저장하는 방법은 배열과 리스트와 튜플, 딕셔너리 등등 다양한 방법이 있다.
그러나 배열과 리스트의 차이가 무엇인지 궁금해서 알아보았다.
C언어에서는 주로 간단하게 배열을 선언할 수 있고, 리스트는 동적 할당을 통해 동적 리스트로 만들어 저장하는 방식을 수행하였다.
그러나 파이썬에서는 우항 데이터에 따라 변수의 자료형이 달라지고, 대괄호로 묶은 데이터를 전달 시 바로 리스트형 변수로 선언 및 저장이 된다.
우선 배열은 크기가 정해져 있고, 한 종류의 데이터 타입만 저장할 수 있다.
그러나, 리스트는 크기가 정해져 있지 않기에 데이터 추가 시 용이하게 추가할 수 있고, 여러 종류의 데이터 타입 값들을 저장할 수 있다.
Numpy 배열 생성
Numpy 라이브러리를 활용하면 파이썬에서도 배열을 생성할 수 있다.
# Numpy 배열 생성
변수명 = np.array(['배열 요소'])
# 예제
np_array = np.array([1, 2, 3, 4])
위 방식으로 배열을 생성할 수 있다.
그럼 위 예제의 데이터 타입과 변수를 출력해보자.
# 데이터 타입 출력
print(type(np_array)) # <class 'numpy.ndarray'>
# 해당 배열 출력
print(np_array) # [1 2 3 4]
위 같은 출력 결과가 나왔다.
데이터 타입은 배열이 아닌 numpy.ndarray라고 출력되었으며, 해당 배열의 값이 출력되었음을 확인할 수 있다.
클래스 생성
클래스란 고유의 속성과 동작을 갖는 데이터 타입이다.
그 말은 클래스 안에 여러가지 속성들과 동작들이 존재한다는 뜻이므로 여러 함수들도 존재할 수 있다는 소리다.
클래스를 학습하기 전 객체의 개념을 알아야 하는데 객체는 클래스를 통해 구체화 된게 객체이다.
예를 들어 빵을 만들기 위해 사용하는 빵틀이 클래스로 비유할 수 있다.
그럼 해당 빵틀로 만든 빵들을 객체로 비유한다.
클래스를 생성하는 방법은 아래와 같다.
# 클래스 생성
class 클래스명:
메서드 선언
클래스를 생성하면 안에 다양한 메서드들을 선언할 수 있다.
클래스를 통해 객체를 생성하면 해당 객체를 통해 클래스의 객체를 사용할 수 있다.
자바에서 클래스를 선언할 때 생성자를 통해 인스턴스를 초기화 하고 각 인수를 속성 값으로 할당할 수 있다.
파이썬에서도 __init__ 메서드를 사용하여 위 같은 방식을 사용할 수 있다.
class 클래스명:
# __init__ 메서드
def __init__(self, 인자1, 인자2...)
self.변수1 = 인자1
self.변수2 = 인자2
위 같은 방식을 통해 생성자와 같은 기능을 수행할 수 있다.
선형회귀
선형회귀란 x가 입력 y이 출력인 그래프에서 데이터들을 가장 잘 표현하는 직선이나 곡선을 찾는 것이다.
주로 직선에서는 y = wx + b의 형태를 띄고 있다.
w는 가중치이고 b는 편향을 나타낸다.
선형 회귀에는 크게 두가지 종류가 존재한다.
1. 단순 선형 회귀 : 독립변수가 하나인 경우
2. 다중 선형 회귀 : 독립변수가 여러 개인 경우
직선 형태의 선형회귀는 단순 선형 회귀이다.
다중 선형 회귀는 주로 y = a + ax1 + ax2 + ax3... 형태로 되어있다.
그렇기에 회귀의 종류에서는 선형 뿐만 아니라 비선형도 존재한다.
손실함수
손실함수는 선형회귀로 모델이 예측한 값과 실제 데이터 값의 차이를 제곱하여 합한 값이다.
그렇기에 이차함수 형태를 띄고있다.
그만큼 모델이 예측한 값과 데이터의 거리가 멀다면 손실이 큰 경우이며, 그 반대의 경우에는 손실이 작다.
손실함수가 작으면 그만큼 모델이 정확한 예측을 할 수 있다.
그래서 그만큼 손실함수를 최소화 하는 과정이 중요하다.
그러면 손실함수를 최소화 하려면 어떤 과정을 수행해야 할까?
경사 하강법
위에서 설명했듯 손실함수는 이차함수의 형태로 되어있다.
그럼 해당 이차함수에서 손실을 최소화 하기 위해 최적의 가중치와 편향을 찾아내야 한다.
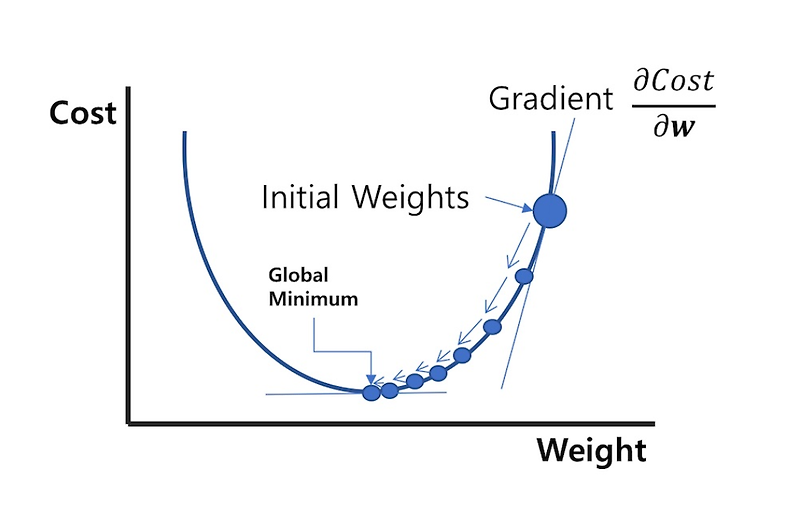
이차함수 그래프에서 가장 낮은 손실을 찾는 방법은 미분을 통한 방법이다.
미분을 통해 기울기가 0에 가까울 수록 그만큼 손실이 줄어들 것이다.
일반적으로 선형 회귀의 손실 함수는 이차함수의 형태를 가지지만, 예외적으로 사차 함수의 형태를 가질 수 있다.
그런 경우에는 기울기가 0인 부분이 2개가 존재할 수 있으므로 전역 최소값과 국소 최소값을 따져봐야 한다.
경사 하강법 구현
파이썬에서 Numpy를 사용하여 경사 하강법을 구현할 수 있다.
import numpy as np
import matplotlib.pyplot as plt
X = np.array([0.0, 1.0, 2.0])
y = np.array([3.0, 3.5, 5.5])
W = 0 # 기울기
b = 0 # 절편
lrate = 0.01 # 학습률
epochs = 1000 # 반복 횟수
n = float(len(X)) # 입력 데이터의 개수
for i in range(epochs):
y_pred = W * X + b # 예측값
dW = (2/n) * sum(X * (y_pred - y))
db = (2/n) * sum(y_pred - y)
W = W - lrate * dW # 기울기 수정
b = b - lrate * db # 절편 수정
# 최종 기울기 및 절편 출력
print(W, b)
# 최종 예측값을 시각화
y_pred = W * X + b
plt.scatter(X, y)
plt.plot([min(X), max(X)], [min(y_pred), max(y_pred)], color='red')
plt.show()
해당 코드를 통해 가장 손실이 낮은 기울기와 절편을 찾을 수 있고, 데이터에 가장 잘 맞는 선형을 찾을 수 있다.
sklearn - datasets 모듈을 사용한 머신러닝 예제(분류)
sklearn의 datasets 모듈에는 다양한 머신러닝 기본 예제를 가지고 있다.
그 중에서도 Iris 데이터셋을 사용하여 꽃의 종류를 분류하는 예제를 풀어보고자 한다.
# 데이터셋 로드
from sklearn import datasets
# Iris 데이터셋 불러오기
iris = datasets.load_iris()
print(iris)
우선 위 코드를 통해 데이터셋을 불러와 출력해보았다.


우선 해당 데이터셋을 살펴보면 딕셔너리 형태로 데이터들이 저장되어 있다.
그 중에서도 data의 value 값은 해당 꽃들의 특징을 나타내는 데이터들로 4가지 특징을 가지고 있다.
또한 오른쪽 사진의 target을 보면 0부터 2까지의 value가 들어있음을 확인할 수 있다.
그러므로 꽃의 종류가 0부터 2로 3가지 종류로 구분되어 있다.
# 데이터 크기 확인
print(len(iris.get('target')))
print(len(iris.get('data')))
이제 데이터들을 훈련시키기 전에 데이터의 크기를 확인해보자.
해당 데이터들의 크기가 동일하다면 이제 데이터를 훈련시킬 준비는 끝나게 된다.
이제 데이터셋을 분할하여 훈련 데이터와 테스트 데이터로 나누어야 한다.
# 데이터셋 분할
(x_train, x_test, y_train, y_test) = train_test_split(iris.data, iris.target, test_size=0.2)
train_test_split 함수를 사용하여 데이터를 훈련 데이터와 테스트 데이터로 나눈다.
훈련 데이터는 모델을 학습시키기 위해 사용한다.
또한 테스트 데이터는 모델의 성능을 평가하기 위해 사용한다.
데이터 셋의 크기 중 test_size로 설정한 만큼만 테스트 데이터로 할당되며 나머지는 훈련 데이터로 할당된다.
이때 데이터를 굳이 훈련 데이터와 데트스 테이터로 나누어야 하는 이유는 테스트 데이터는 모델 성능을 평가할 때 사용되기 때문에 이미 정답을 알고있는 테스트 데이터를 훈련시키면 공정한 학습이 될 수 없기 때문이다.
그렇기에 학습 데이터로만 학습 후 테스트 데이터로 비교하기 위해 나누는 것이다.
이제 학습데이터를 활용하여 학습시켜 보자.
이때 KNN 분류기를 사용하여 해당 분류기를 학습시킬 것이다.

KNN 분류기는 위 사진과 같이 해당 점에서 설정한 값만큼 데이터가 포함될 때까지 원을 점점 늘려가 데이터를 분류하는 분류기이다.
사진에서처럼 K=3 일 경우에는 Case B의 경우가 3개이므로 해당 데이터는 Case B로 분류한다.
이때 K의 값을 할당할 때는 홀수의 갯수만큼 할당하는게 좋다.
짝수의 경우에는 데이터의 갯수가 같으므로 분류하기가 쉽지 않기 때문이다.
이제 학습 데이터들을 가지고 KNN 분류기를 학습시켜 보자.
from sklearn.neighbors import KNeighborsClassifier
# 가장 가까운 5개의 이웃을 고려
knn = KNeighborsClassifier(n_neighbors=5)
# 학습데이터를 통한 학습
knn.fit(x_train, y_train)
이제 예측 결과를 확인해보자.
# 예측 수행 및 데이터 저장
y_pred = knn.predict(x_test)
print(y_pred) # 예측 데이터
print(y_test) # 실제 데이터

아쉽게도 예측 데이터에서 1개가 틀렸다.
그러나 1개를 제외한 모든 데이터는 테스트 데이터와 비슷하게 출력되었으므로 높은 정확도를 가진 것을 볼 수 있다.
'Python > 데이터분석(ABC 부트캠프)' 카테고리의 다른 글
| [20일차] ABC 부트캠프 / 제 2회 ESG Day (2) | 2024.07.21 |
|---|---|
| [19일차] ABC 부트캠프 / sklearn의 datasets 모듈 예제 (0) | 2024.07.21 |
| [17일차] ABC 부트캠프 / 빅데이터 분석 및 기초 통계, 딥러닝 기초 (0) | 2024.07.21 |
| [16일차] ABC 부트캠프 / 데이터 수집 및 시각화 팀 프로젝트 (0) | 2024.07.17 |
| [15일차] ABC 부트캠프 / 건양대학교 견학 (0) | 2024.07.14 |
